変換コマンド
タブ/空白置換 (:expandtab, :unexpandtab)
行単位でタブ←→空白の変換を行います。 vim では set expandtab → :retab などで同様の変換が行えますが、 本エディタでは :retab コマンドは実装していません。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :expandtab [<n>] | :exp | タブ→空白変換 | 行 | uvw固有 |
| :unexpandtab [<n>] | :une | 空白→タブ変換 | 行 | uvw固有 |
- <n> には変換するタブ幅を指定します。(指定されない場合には tabstop パラメータの値が使われます)
- exptandtab パラメータの状態と無関係に変換します。
- noignorequote, nojignorequote パラメータで引用符内は変換から除外することが出来ます。
コマンド例:
:%expandtab
:'<,'>unexpandtab 4
関連パラメータ:
| パラメータ | 省略形 | 形式 | 説明 | 初期値 | 備考 |
|---|---|---|---|---|---|
| ignorequote | iq | 二値 | 引用符を通常の文字として扱います。noignorequote でダブルクォート(")、シングルクォート(')、バッククォート(`) で括られた範囲を変換から除外します。 | ignorequote | |
| jignorequote | jiq | 二値 | 全角引用符を通常の文字として扱います。nojignorequote で全角の引用符「」“”‘’などで括られた範囲を変換から除外します。 | jignorequote |
全角/半角間の空白調整 (:jspace, :junspace)
行単位の処理で、半角と全角文字の間に空白を挿入/削除するような整形を行います。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :jspace | :js | 半角と全角の間に空白を挿入します。 | 行 | uvw固有 |
| :junspace | :jun | 半角と全角の間の空白を削除します。 | 行 | uvw固有 |
- 半角/全角間に単純に空白を挿入/削除するのではなく、禁則文字前後で調整をするようになっています。 行末禁則文字の直後は除外し、行頭禁則文字の直前も除外するようになっています。
- jspcignore パラメータで前後を調整対象外とする文字を指定することが出来ます。
- noignorequote, nojignorequote パラメータで引用符内は変換から除外することが出来ます。
コマンド例:
:%jspace
:'<,'>junspace実行例(禁則文字):
あいう(えお
:jspace
あいう (えお
↑↑
│└ こちらは空白を挿入しない。
└─ こちらは全角/半角間に空白を挿入する。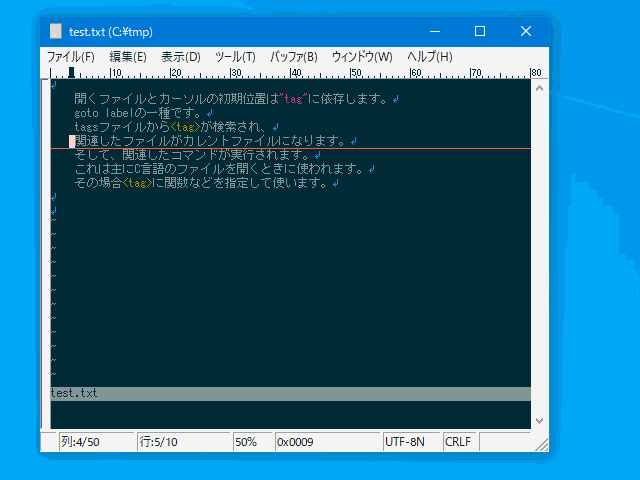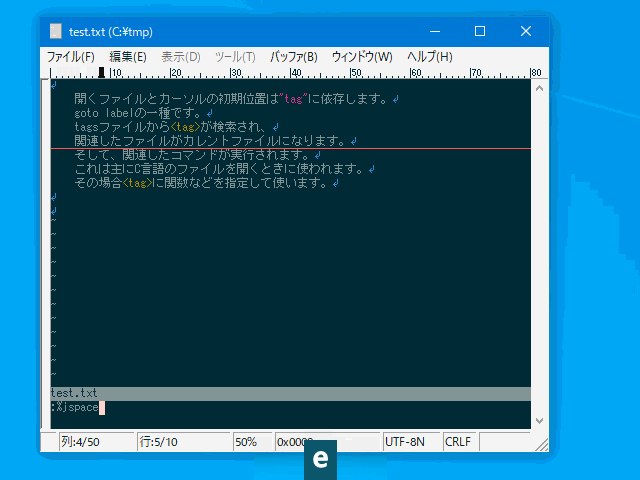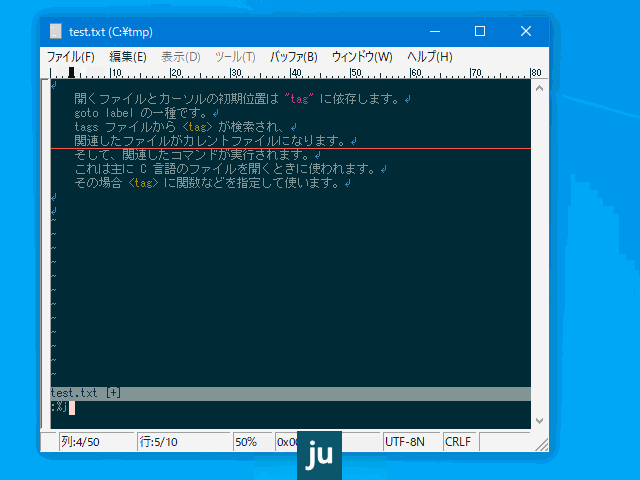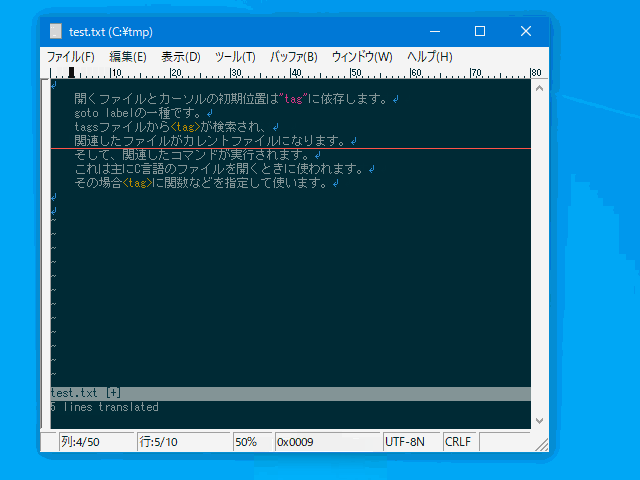
関連パラメータ:
| パラメータ | 省略形 | 形式 | 説明 | 初期値 | 備考 |
|---|---|---|---|---|---|
| ignorequote | iq | 二値 | 引用符を通常の文字として扱います。noignorequote でダブルクォート(")、シングルクォート(')、バッククォート(`) で括られた範囲を変換から除外します。 | ignorequote | |
| jignorequote | jiq | 二値 | 全角引用符を通常の文字として扱います。nojignorequote で全角の引用符「」“”‘’などで括られた範囲を変換から除外します。 | jignorequote | |
| jspcignore | jsi | 文字列 | :jspace, :junspace で空白の挿入/削除から除外する文字を指定できます。 | #$&()-/@[\]^{|}~ |
全角/半角変換 (:hanzen, :zenhan (:hankaku, :zenkaku))
コマンドでは行単位で、 英字/数字/アスキー記号/カタカナの全角←→半角変換を行います。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :zenhan | :ze | 全角→半角の変換を行います。(zoption で指定された文字種が対象) | 行 | uvw固有 |
| :hankaku | (全角→)半角への変換を行います。(:zenhan のエイリアス) | 行 | uvw固有 | |
| :hanzen | :ha | 半角→全角の変換を行います。(zoption で指定された文字種が対象) | 行 | uvw固有 |
| :zenkaku | (半角→)全角への変換を行います。(:hanzen のエイリアス) | 行 | uvw固有 |
- :hankaku、:zenkaku のエイリアスは後になって Kaoriya 版 vim のプラグインで そういう名前のコマンドがあるのに気付いたので互換で入れたのですが 省略形が真逆になるのでどうしたものか…。
Visual モードでの選択後に gZ, gH コマンドによって 文字単位、行単位、ブロック単位で変換することも可能になっています。
| normal コマンド | 説明 | 変換単位 | 備考 |
|---|---|---|---|
| gH | 全角→半角の変換を行います。(zoption で指定された文字種が対象) | 文字、行、ブロック | uvw固有 |
| gZ | 半角→全角の変換を行います。(zoption で指定された文字種が対象) | 文字、行、ブロック | uvw固有 |
- zoption パラメータで半角/全角変換の対象と文字種の組み合わせを指定することができます。
- noignorequote, nojignorequote パラメータで引用符内は変換から除外することが出来ます。
コマンド例:
:%zenhan
:'<,'>hanzen実行例(英字、数字、アスキー記号を半角に変換)
:set zoption=7
ABC#123
:zenhan
ABC#123実行例(半角カナを全角に変換)
:set zoption=8
コマンド
:hanzen
コマンド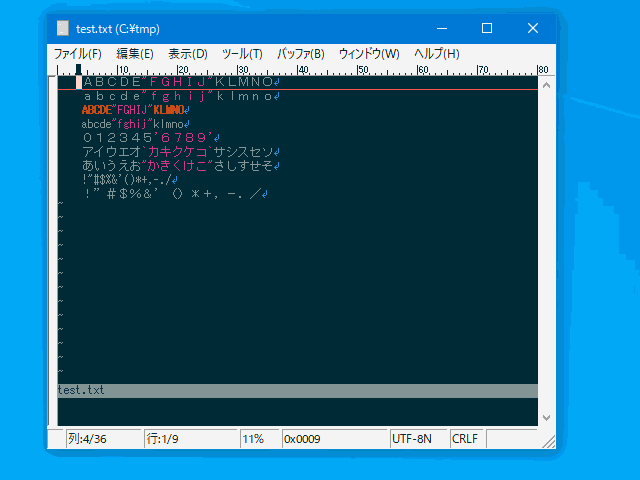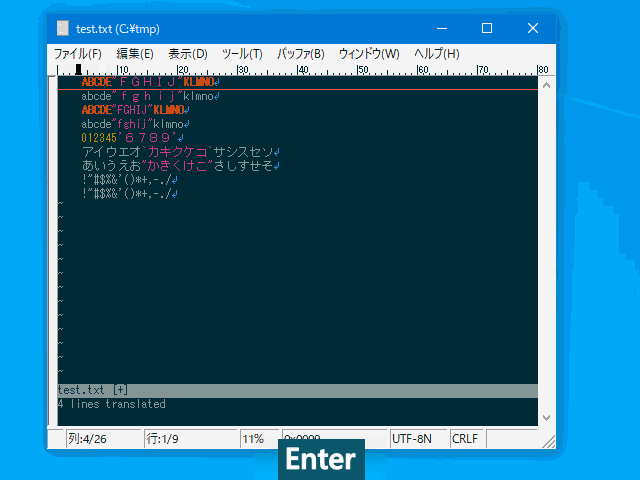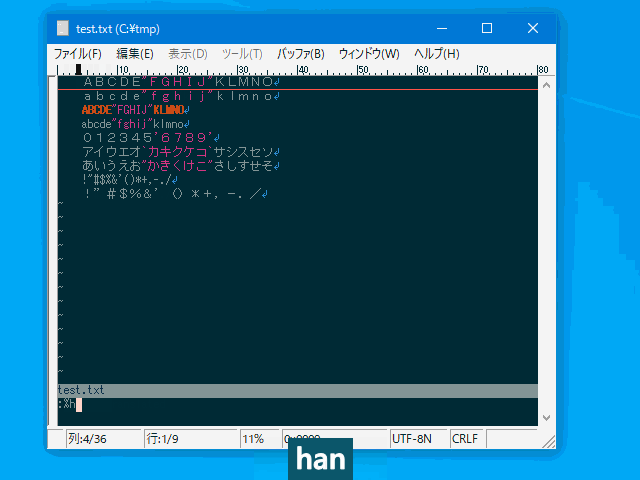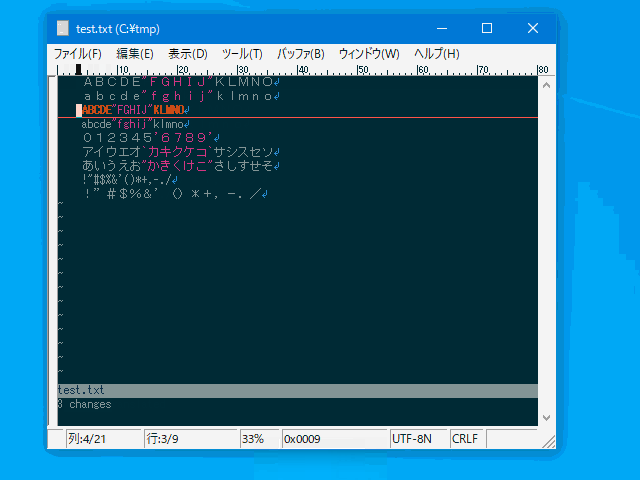
関連パラメータ:
| パラメータ | 省略形 | 形式 | 説明 | 初期値 | 備考 |
|---|---|---|---|---|---|
| ignorequote | iq | 二値 | 引用符を通常の文字として扱います。noignorequote でダブルクォート(")、シングルクォート(')、バッククォート(`) で括られた範囲を変換から除外します。 | ignorequote | |
| jignorequote | jiq | 二値 | 全角引用符を通常の文字として扱います。nojignorequote で全角の引用符「」“”‘’などで括られた範囲を変換から除外します。 | jignorequote | |
| zoption | zopt | 数値 | 半角/全角変換の組み合わせをビットで指定します。デフォルトは 7 で英字、数字、アスキー記号が対象になっています。 | 0 |
zoption のフラグ:
0: 変換なし
1: 英字を全角/半角変換する。
2: 数字を全角/半角変換する。
4: アスキー記号を全角/半角変換する。
8: カタカナを全角/半角変換する。
デフォルト値: 7 = 1(英字) + 2(数字) + 4(アスキー記号)並べ替え (:permutate)
fieldseparator パラメータ指定のセパレータで区切られた要素を 行内で並べ替えを行います。 (awk の print 構文のようなものだと思ってください。)
実際には vim の正規表現 \( \) でも同様のことが出来ますが それを簡単に実行するための機能だと思ってください。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :permutate <str> | :perm | 行内で要素の並べ替えを行います。 | 行 | uvw固有 |
- fieldseparator パラメータ指定のセパレータで分割された要素が 順番に $1 $2 $3 ... に割り当てられますので :permutate コマンドの引数で好きな順序のフォーマットを指定してください。 ($<n> 以外はフリーフォーマットです。$0 は行全体を表します。)
- noignorequote, nojignorequote パラメータで引用符内は分割から除外することが出来ます。 ダブルクォート(")、シングルクォート(')、バッククォート(`)で 括られた文字列は 1 要素とみなされ、 引用符中の fieldseparator で分割されることはありません。
- fieldseparator
が空の場合(デフォルト)は、連続した半角空白及びタブ文字がセパレータとなります。
単一の半角空白やタブ文字をセパレータとしたい場合には
記号でエスケープした
\␣や\\tを使ってください。
コマンド例:
:%permutate $2 $1 $3
:'<,'>permutate p3=$3, p2=$2, p1=$1
:set fieldseparator=\
:set fieldseparator=\\t実行例(CSV を並び替え)
:set fieldseparator=,
ABC,DEF,GHI
:perm $2,$1,$3
DEF,ABC,GHI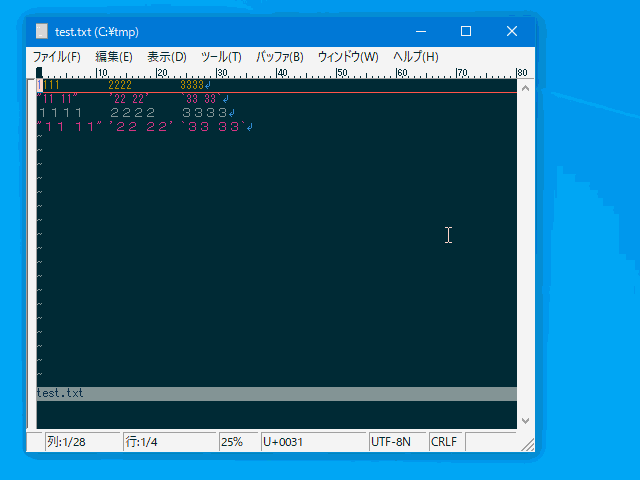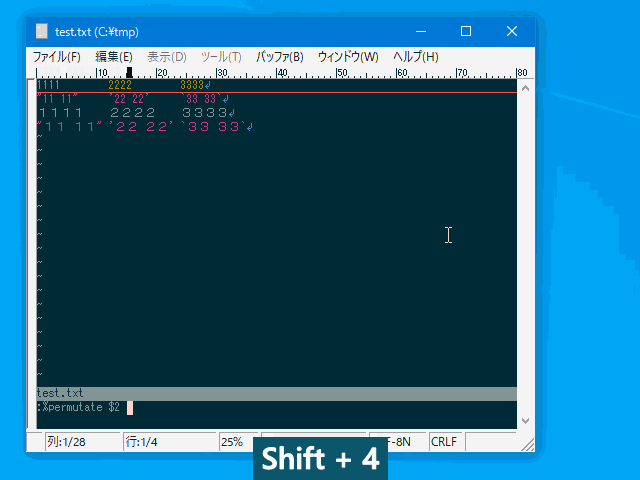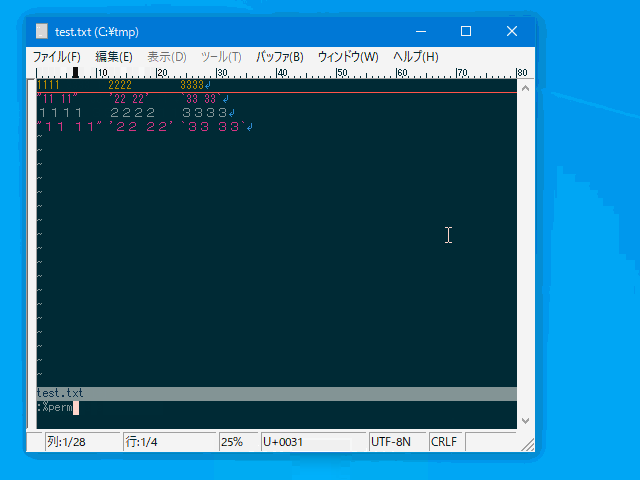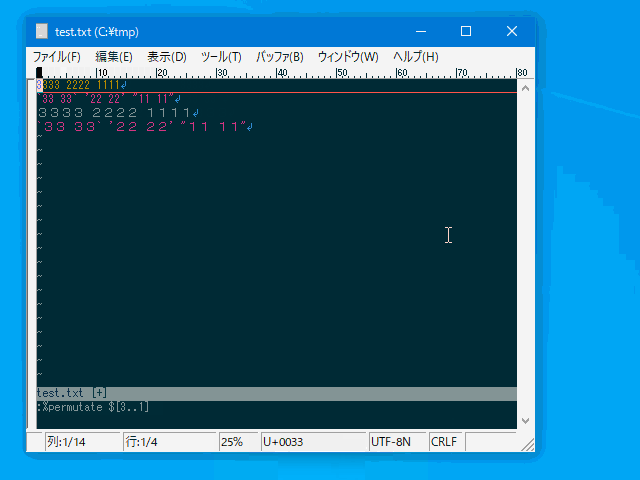
関連パラメータ:
| パラメータ | 省略形 | 形式 | 説明 | 初期値 | 備考 |
|---|---|---|---|---|---|
| fieldseparator | fs | 文字列 | :permutate コマンドで要素を分割する際のセパレータを指定します。デフォルトは空で、半角空白及びタブ文字がセパレータになっています。 | 空 |
行頭/行末空白切り詰め (:trim, :ltrim, :rtrim, :mtrim)
行頭と行末の空白文字を切り詰めます。 普通に :%s/^\s\+//
:%s/\s\+$// でも切り詰めできるのですが、
簡略化のためと単純な処理なので正規表現を使うより早くなるので
別コマンドとして実装しています。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :trim | :tri | 行頭/行末の空白文字を切り詰める。 | 行 | uvw固有 |
| :ltrim | :lt | 行頭の空白文字を切り詰める。 | 行 | uvw固有 |
| :rtrim | :rt | 行末の空白文字を切り詰める。 | 行 | uvw固有 |
| :mtrim | :mt | 行頭以外の連続した空白文字を 1 文字の空白に切り詰める。 | 行 | uvw固有 |
- 現時点では全角空白は切り詰めないようになっています。(\s の扱いと同じ)
コマンド例:
:%trim
:'<,'>ltrim
:'<,'>rtrim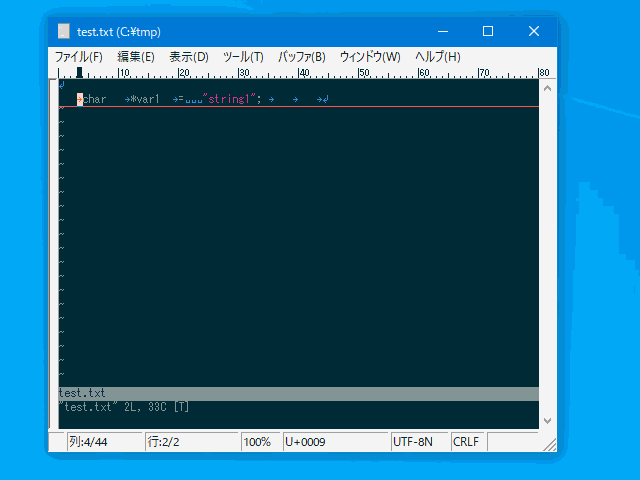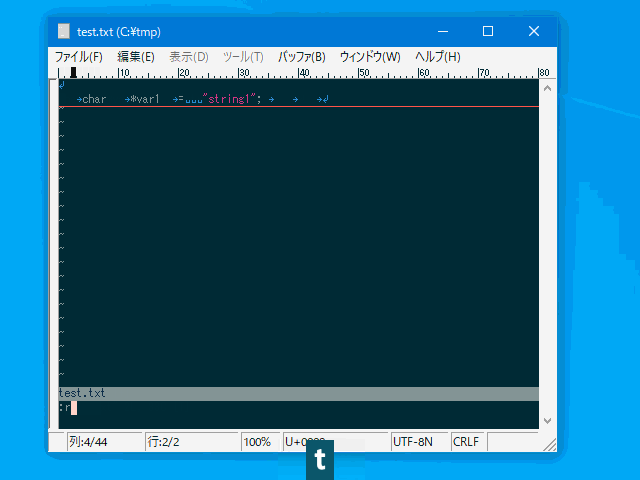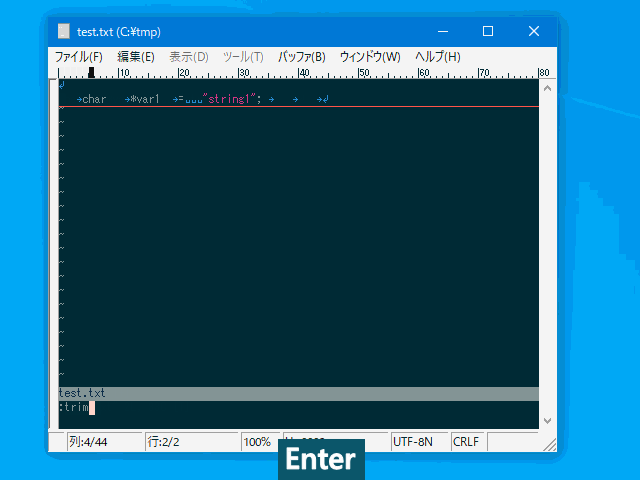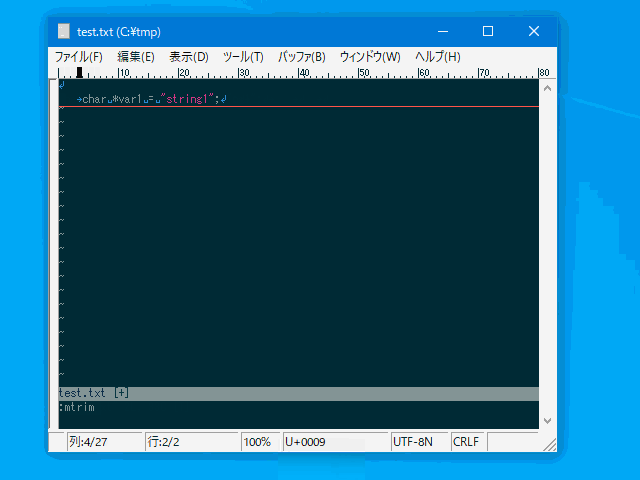
連続した空行を一行にまとめ (:uniqblankline)
単なる空行の削除であれば :g/^\s*$/d で出来ますが、
整形の際に空行は空行として 1 行だけは残したい、
というケースに対応するためのコマンドです。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :uniqblankline | :uniqbl | 連続した空行を一行にまとめる。 | 複数行 | uvw固有 |
- 単なる空行と、半角空白/タブのみの行を一行にまとめます。
- 現時点では全角空白は空白とは見做されません。(\s の扱いと同じ)
コマンド例:
:%uniqblankline
:'<,'>uniqbl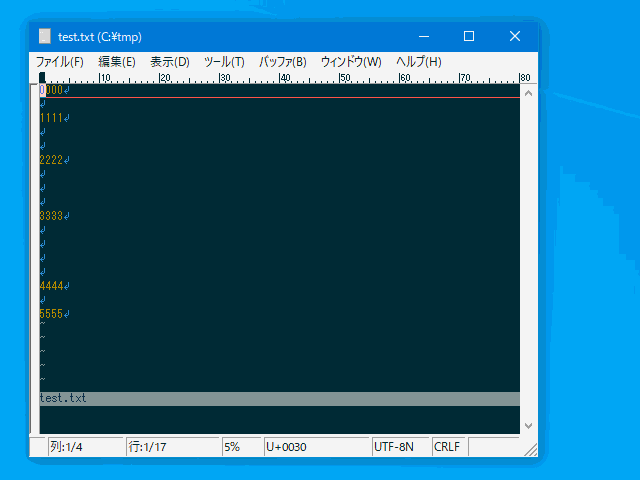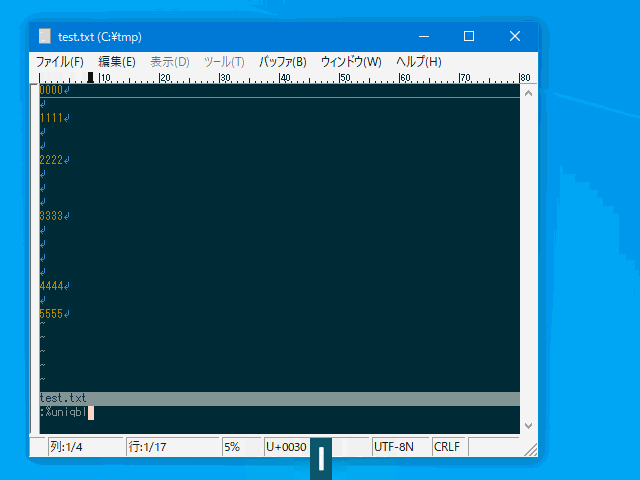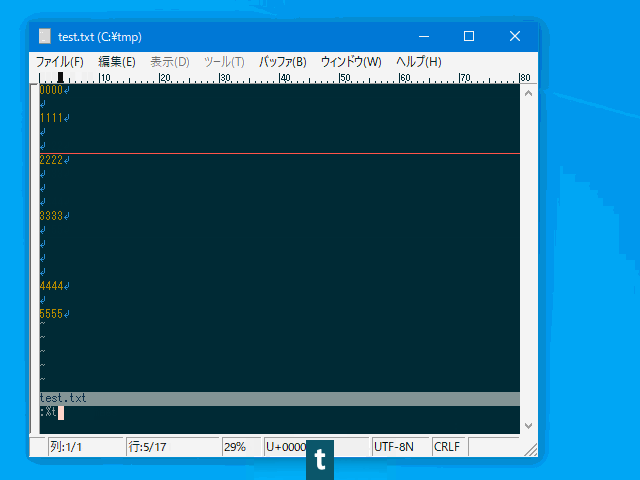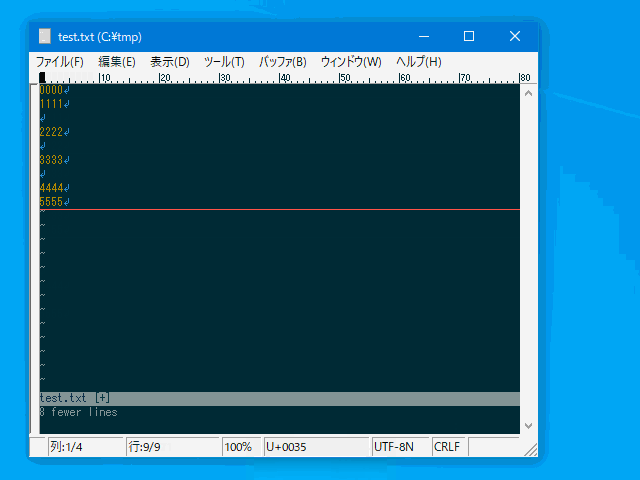
連続した空行を一行にまとめ (:trimblankline)
:uniqblankline の亜種です。空行が複数行連続する場合は 1 行にまとめますが、 空行が 1 行のみだった場合はその空行を削除します。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :trimblankline | :trimbl | 単一空行を削除し、連続空行を 1 行にまとめる。 | 複数行 | uvw固有 |
- 単なる空行と、半角空白/タブのみの行を一行にまとめます。
- 現時点では全角空白は空白とは見做されません。(\s の扱いと同じ)
コマンド例:
:%trimblankline
:'<,'>trimbl文字セット置換 (:y///)
sed コマンドの y コマンドを試しに実装してみただけのものです。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :y/<set1>/<set2>/ | <set1> の文字を <set2> の同じ位置にある文字に置換します。 | 行 | uvw固有 |
- <set1> と <set2> が同じ文字数である必要があります。
- 文字の列挙の他、ハイフン(-)で範囲指定もできます。
- :y 単独か :y に空白が後続する場合は :yank の意味になります。
コマンド例:
:%y/ABCDE/edcba/
:'<,'>y/a-z/z-a/
:'<,'>y/z-a/a-z/URL エンコード変換 (:urlencode, :urldecode)
URL のエスケープ文字へのエンコード・デコードを行います。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :urlencode | :urle | URL のエスケープ文字へのエンコードを行います。 | 行 | uvw固有 |
| :urldecode | :urld | URL のエスケープ文字からのデコードを行います。 | 行 | uvw固有 |
- エンコード(:urlencode)の際には現在のエンコーディング(jcode)に沿ってエンコードを行います。
- デコード(:urldecode)の際にはなるべく自動判定するようにしていますが、 判定できない場合には現在のエンコーディング(jcode)でデコードするようになっています。
コマンド例:
:%urlencode
:'<,'>urldecode実行例:
https://wiki.archlinux.jp/index.php/Vim?rdfrom=https://wiki.archlinux.org/index.php?title=Vim_(%E6%97%A5%E6%9C%AC%E8%AA%9E)&redirect=no
:urldecode
https://wiki.archlinux.jp/index.php/Vim?rdfrom=https://wiki.archlinux.org/index.php?title=Vim_(日本語)&redirect=noUnicode 文字変換 (:uniencode, :unidecode)
Unicode コードポイント形式へのエンコード/デコードを行います。 単純に U+xxxxx 等がテキスト中に書かれていた場合に 何の文字かを見るためだけに実装しています。
| コマンド | 省略形 | 説明 | 変換単位 | 備考 |
|---|---|---|---|---|
| :uniencode | :unie | 文字を Unicode コードポイント形式に変換します。 | 行 | uvw固有 |
| :unidecode | :unid | Unicode コードポイント形式を該当する文字に変換します。 | 行 | uvw固有 |
- エンコード(:uniencode)では文字を
\u{xxxx}形式に変換します。 - デコード(:urldecode)では
U+xxxx\uxxxx\u{xxxx}形式を 該当する文字に変換します。 - 本当は文字単位で変換できるようにした方が良いのでしょうが、 キーバインドが足りないのでコマンドで行単位の処理になっています。
コマンド例:
:uniencode
:%unidecode実行例:
U+2603 SNOWMAN
:unidecode
☃ SNOWMAN